Structuring Changes With The Code Reviewer in Mind
In most engineering organizations, if you want to ship anything, you’ll need to get your changes reviewed first. There’s been a lot written about why code reviews are important, and how to give and receive them effectively (a few that I’ve found helpful can be found here, here, and here). But there’s been comparatively less written about how you, as a programmer, can structure your changes to make the reviewer’s job easier, enabling them to get back to you faster, with higher quality feedback. Nearly everyone agrees that small changes tend to be easier to review than large ones, and there’s even some data to back this up. But breaking up your change into smaller revisions can be difficult: even the simplest refactors can necessitate huge diffs if the abstraction you’re changing is widely used. Moreover, breaking your change up into smaller pieces alone may not be sufficient. While this is too deep of a topic to try to cover comprehensively, here are some techniques that I’ve found helpful as both as a code author and code reviewer.
Separate Semantic Changes From Refactors
At a high level, there are two reasons you might want to make changes to an existing codebase:
to change the semantics of the program (e.g. new features, bug fixes, etc.)
to change the organization of the program (i.e. refactors)
The best way to reduce cognitive overhead for your reviewer is to decide whether to alter the program’s semantics or its organization, and to ensure every line you change is consistent with that decision. Reviewing new and/or changing business logic requires a different kind of scrutiny than reviewing changes to the expression of existing, battle-hardened business logic. You would rather your reviewer spend their limited time and energy on more valuable things than trying to infer the intention behind each line of your diff and context switching.
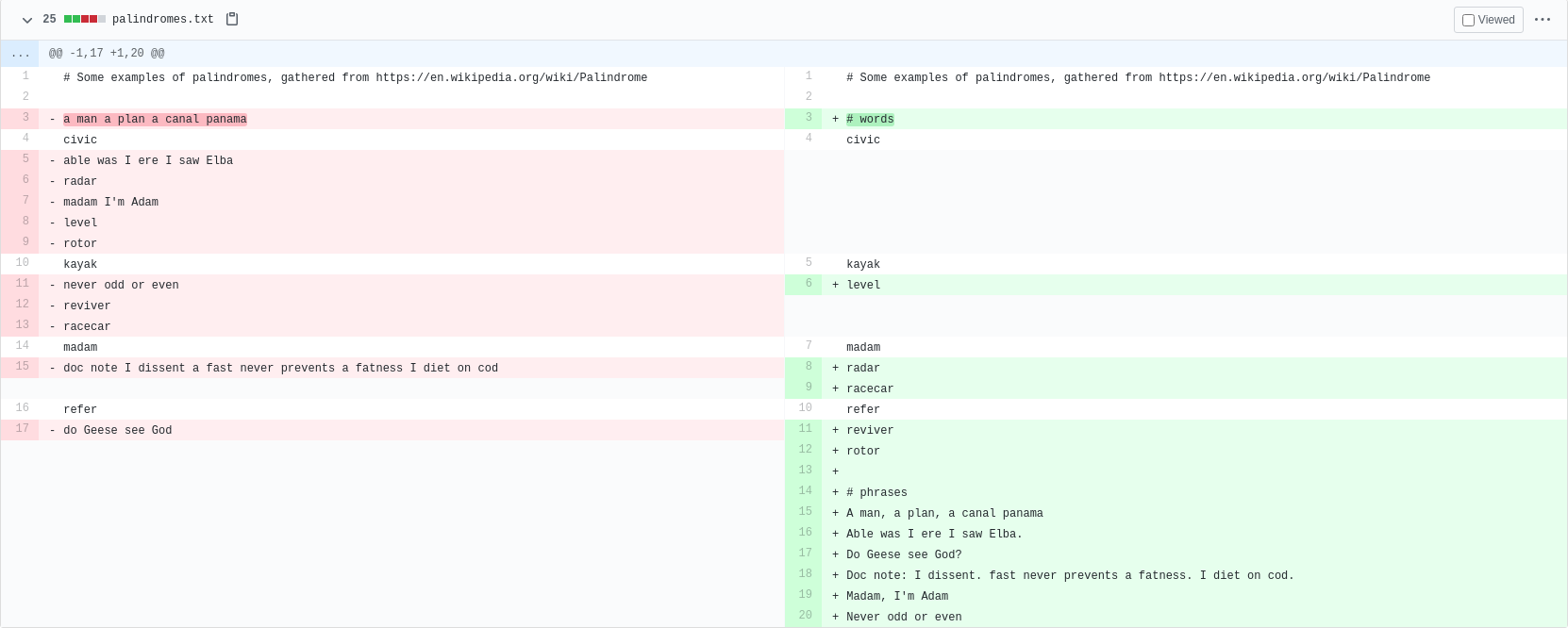
Consider an example based on a file with the following contents. This is just a text file with a set of palindromes in it and not real code, but for the sake of keeping this example simple, let’s suspend disbelief and pretend that it is.

There are two kinds of palindromes here: words (which have no whitespace or punctuation, and are identical when read forwards and backwards), and phrases (which read the same forwards an backwards if you ignore whitespace, punctuation, and capitalization). We want to add a new feature to this file: adding appropriate punctuation to each phrase by capitalizing, adding periods to the end of complete sentences, etc. Along the way, we realize that this would be easier if the file were better organized: words and phrases should be grouped together separately, and each group should be sorted alphabetically. Here’s what it might look like if we attempt to make all of these changes at once.
a diff with both a refactor and a new feature
This change is unnecessarily hard to review, even though it’s pretty small in terms of lines of code modified. The reviewer needs to verify:
that the results have the same palindromes as before, but not exactly the same because some of them were modified on purpose
the correctness of those modifications
that every palindrome is correctly grouped
that the groups are alphabetized
This will likely take multiple passes, and the overhead keeping track of where the reviewer is in each pass leaves them with fewer cognitive resources available for the review work itself. This is all assuming that they find the changes desirable. Ideally the high-level approach is something that’s been discussed with the reviewer well before code review, but miscommunications sometimes happen, and it’s always reasonable to expect constructive criticism about particulars. Coming to an agreement around any one change can hold up the entire review, delaying everyone from benefiting from the hard work that’s gone into everything else.
Let’s break this change up into two reviews: one for a refactor, and the other for a new feature. We’ll look at the refactor first.

A diff for a refactor
Although this diff isn’t any smaller than the combined diff, it is considerably easier to review, especially if the review is accompanied by a note along the lines of “I grouped and alphabetized the palindromes using cut-and-paste.” Cutting-and-pasting is unlikely to result in typos, but it can result in accidentally deleting or duplicating existing lines. So all the reviewer needs to do here is:
verify that the total number of palindromes hasn’t changed
subtracting line numbers makes this easy
check that each group is alphabetized without any consecutive duplicates
just a quick visual scan
In this case, the misalphabetization of “radar” and “racecar” is easy to catch and to fix.
Let’s look at the new feature.

A diff for the new feature
The diff is small, but the changes are substantive. The reviewer needs to carefully read every modified line to verify that the capitalization and punctuation are correct. But, because this is the only thing they are asked to do, it’s far easier for them to find the serious bug (which results in one of the phrases no longer being a palindrome) in this diff than in the original.
In principle, the original change could be broken down even more by decomposing the refactor into two smaller pieces: one to alphabetize, one to group. Because these are both semantics-preserving changes, it’s a matter of taste whether this would result in an easier sequence of reviews; when it doubt, defer to the reviewer’s preference. That said, combining either of these smaller refactors with the new feature would have resulted in nearly as gnarly of a review as the original.
We’ve seen that combining semantics-altering changes with semantics-preserving changes is best avoided, no matter how tempting it can be to “fix things up along the way” while doing something else. If that fix-up really is worth doing, then it’s worth its own stand-alone review.
Quality Checks For Reviewable Code
The code reviewer should never waste time asking themselves "How does this even make sense at all?" when the answer is "it doesn't." It should always be clear whether the code builds, passes tests (both old and new), passes linting rules, etc. Hopefully, the code review environment is integrated with a CI system that performs these "quality checks" automatically, rendering this a non-issue. If not, investing in this tooling will pay for itself quickly.
Keeping Reviews Small When They Can’t be Self-Contained
Ideally, any change submitted for review should be small, so that it’s easy to reason about, and self-contained, so that the motivation for making it is clear. Unfortunately, these two ideals are sometimes in tension, especially in large, complex projects. While it might be clear to the code author that a series of refactors and new abstractions will make it easier to build a nontrivial new feature, we’ve already seen that combining them into one self-contained change can result in an unmanageable review. But merely breaking up this work into a series of small changes can also end up leaving the reviewer feeling lost. “What’s this new abstraction for, and how do I know that it’s the right one?” is sometimes hard to answer without seeing it used in context. But where should that context live, if not in the code review itself? One tactic for managing this complexity is to use the following workflow.
Create a self-contained “spike” branch. You should be confident that the resulting code is correct, and that it has the most important functionality of the eventual finished product. It should be no larger than necessary, but does not need to be small, and can combine refactors with new features. The spike branch doesn’t need to quite live up to the standards of production-quality of shippable code because it will never be merged. Eventually, you will throw it away.
Split off one or more small changes from the spike branch that are independently reviewable in parallel. If the motivation for these changes isn’t self-evident, link to examples of how they will be used in the spike branch in the code review.
(Optional) Once the changes from step #2 are reviewed and shipped, you may want to rebase the spike branch to pick up any changes made during code review before repeating step 2. This shrinks the size of the spike’s diff from the main branch. However, if the spike drifts far enough the main branch that merge conflicts become an issue, this may not be worth the effort.
Go back to step 2, until all of the spike branch’s functionality has been merged.
We’ve already seen a small example of this workflow in the previous section. The original combined diff was the spike branch. The refactor was the first independently reviewable change, which is motivated by the subsequent new feature. The new feature could have been prepared either from scratch, or by rebasing the spike branch off of the final, bug-fixed version of the refactor branch.
Building a working prototype quickly de-risks the project and provides context for a series of small reviews. Those reviews may not be fully self-contained, but they will be understandable. And while spike branch is likely to be long-lived, and long-lived branches can be expensive to maintain, the spike branch’s disposability makes that maintenance largely optional.
Reviewing By Commit
The spike branch process can feel heavyweight, especially in environments where the process of merging approved code is slow. One alternative is to submit one branch for review with self-contained, independently reviewable commits. Beyond reducing the number of merge-and-rebase cycles, the benefit of this approach is that the reviewer may be able to keep more context in short-term memory than if each change were reviewed independently. However, most CI systems don't automatically perform quality checks on every commit, which sacrifices some self-containedness. The reviewer may have nontrivial feedback, and keeping track of the approval state for each commit and its revisions quickly becomes a burden. Back-and-forths about any one commit delays merging all of them, preventing everyone from benefiting from changes that are otherwise ready to ship. This technique is safe to avoid, and best reserved for those niche situations where you have a series of simple, non-controversial changes that build on top of one another, and remain small even when taken together.
Putting it All Together
Your goal is to make code review as simple and straightforward for the reviewer as possible. We've seen that lines of code is an imperfect measure of complexity, and that there are some techniques you can use to manage that complexity. Avoid combining multiple unrelated changes into the same review. Even though "is this best thought of as one change or as multiple changes?" can sometimes have a subjective answer, if you find yourself refactoring at the same time as doing feature work or bug fixes, you know that the answer to that question is "multiple changes.” If, while developing, you find yourself changing lots of things because you won't know for sure how everything should look until all of it’s done: don't sweat it. Just split it into pieces when you’re done, make sure that each piece passes quality checks, and link to whatever is yet-to-be-reviewed-so-far for context when helpful.